learning phrase representing rnn encoder decoder
CNN
- RNN은 히든 노드가 방향을 가진 엣지로 연결돼 순환구조를 이루는 인공신경망의 한 종류
- 음성, 문자 등 순차적으로 등장하는 데이터 처리에 적합한 모델
- 시퀀스 길이에 관계없이 인풋과 아웃풋을 받아들일 수 있는 네트워크 구조
- RNN은 관련 정보와 그 정보를 사용하는 지점 사이 거리가 멀 경우 역전파시 vanishing gradient problem 발생.
Abstract
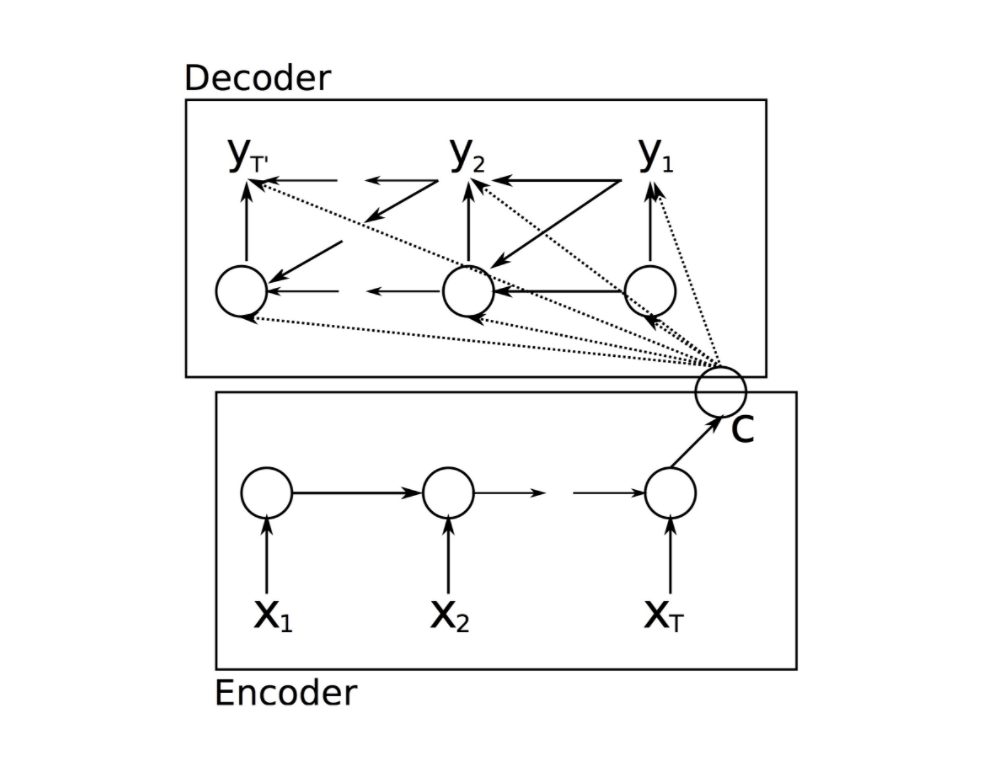
- RNN Encoder-Decoder는 두가지 네트워크로 구성되어있다.
- Encoder는 일련의 기호(문장)들을 고정된 길이의 벡터로 만든다
- Decoder는 고정된 백터를 일련의 기호(문장)으로 만든다.
- 프랑스어로 이루어진 문장을 입력하면 영어로 번역한 문장을 뱉는 개념
- encoder와 decoder는 target문장의 조건부분포를 최대화 하도록 훈련한다.
Introduction
- statistical machine translation(SMT)에서 발전시킨 방법이 Encoder-Decoder를 이용한 방법
- 정교한 hidden unit을 추가함으로써 training을 편하게 한다.
- 기존 번역모델과 RNN Encoder-Decoder를 비교했을 때 문장에서 언어적 규칙들(문법과 의미들)을 더 잘 잡아낸다
RNN Encoder-Decoder
- 확률적 관점에서 조건부분포를 학습시키는 일반적인 방법이다.
$ p( y_1,…,y_t’ \mid x_1,…,x_t)$
- input 과 output의 t,t’은 길이가 다를 수 있다.
$h_t = f(h_{t-1},x_t)$
- f는 nonlinear activation function이다.
- input인 x가 hidden state를 통과하면서 벡터 c가 된다.
-
Decoder는 벡터 c의 영향을 받음. $h_t = f(h_{t-1},y_{t-1},c)$
- encoder decoder 두개의 네트워크는 학습을 진행할 때 log_likelihood를 최대화 하면서 학습해야한다.
$\max_\theta\frac{1}{N}\sum_{n=1}^N logp_\theta(y_n\mid x_n)$
$\theta는 모델 parameter이고 이를 추정하기 위해서 gradient 기반의 알고리즘을 사용할 수 있다.$
Hidden Unit
![]()
- z는 update gate로 새로운 것을 얼마나 반영할지 결정
-
r은 reset gate로 이전의 hidden state를 얼마나 유지할지 결정
- Rnn Encoder-Decoder는 완전히 새로운 번역기를 만드는게 아니라 기존의 SMT시스템의 phrase pair table에 점수를 매기는 부분에만 사용
![]()
- CSLM과 사용했을 때 성능이 가장 좋았다.(BLEU Score는 높을수록 좋다.)
- 두 방법이 독립적으로 성능향상에 기여한다.
Conclusion
- 임의의 길이를 가진 일련의 문장들을 다른 임의의 길이를 가진 일련의 문장들로 mapping하는 새로운 모델을 제안.
- 새로운 hidden unit(reset gate와 update gate로 구성됨)을 제안
- BLEU스코어를 이용한 학습을 진행함으로써 범용적인 Phrase Representation을 가능하게 했다.
- 문장의 문법과 의미를 담아냄
References

Comments